2026.03.19
Prototyping with AaaS Tech Lab | データサイエンスインターン最終カリキュラム
AaaS Tech Labは、博報堂が主催するインターンシップ「データエンジニアリング篇」[1][2]にて、企画や運営などを携わっています。
本インターンでは学生に会社や社員のことをより知ってもらう為、また我々も学生の個性や強みをより深く理解する為、学生に出社していただき交流する日程を設けています。
特に2025年度の最終カリキュラムは「Prototyping with AaaS Tech Lab」と称し、生成AIやCG技術を活用し、学生が主人公であるミュージックビデオ(MV)を制作する実験型の体験作り・プロトタイピングに挑戦しました。
記事では、そんな体験装置開発の裏側や、カリキュラムの様子をご紹介します。

本インターンでは学生に会社や社員のことをより知ってもらう為、また我々も学生の個性や強みをより深く理解する為、学生に出社していただき交流する日程を設けています。
特に2025年度の最終カリキュラムは「Prototyping with AaaS Tech Lab」と称し、生成AIやCG技術を活用し、学生が主人公であるミュージックビデオ(MV)を制作する実験型の体験作り・プロトタイピングに挑戦しました。
記事では、そんな体験装置開発の裏側や、カリキュラムの様子をご紹介します。
体験のコンセプト / 目指した体験
生成AI技術の発展に伴い、AaaS Tech Lab (ATL) はデータサイエンティスト集団から、データサイエンスを軸にアプリケーションや体験をプロトタイピングする集団へ変化しています。また、2週間に1度 誰かが開発・実験・試行錯誤(プロトタイピング)した内容を発表するゼミもATL発足当初から継続しています。
そんな、ATLの日常や文化になりつつあるプロトタイピングを、学生も参加できる体験化することへ挑戦したのが、本取り組みです。
講義や既存事例の展示ではなく、「プロトタイピング自体の体験化」なので、2.5時間をかけ、会場で学生のデータを取るところから始まり、1分半ほどのMVを制作・視聴するところまで実施。
その中で、ATLでのプロトタイピングの面白さを体感してもらい、学生とATLメンバーのコミュニケーションを密にすることを目指しました。
ちなみにMV制作としたのは、AIエージェントやバーチャルヒューマンなどのトレンドを盛り込みつつ、堅くなく分かりやすい体験になりうると考えた為です。
そんな、ATLの日常や文化になりつつあるプロトタイピングを、学生も参加できる体験化することへ挑戦したのが、本取り組みです。
講義や既存事例の展示ではなく、「プロトタイピング自体の体験化」なので、2.5時間をかけ、会場で学生のデータを取るところから始まり、1分半ほどのMVを制作・視聴するところまで実施。
その中で、ATLでのプロトタイピングの面白さを体感してもらい、学生とATLメンバーのコミュニケーションを密にすることを目指しました。
ちなみにMV制作としたのは、AIエージェントやバーチャルヒューマンなどのトレンドを盛り込みつつ、堅くなく分かりやすい体験になりうると考えた為です。


構成技術の概要
下図にある通り、大きく「音楽」「CGモーション」「モーション動画」の3要素に分けて、開発や体験作りを進行しました。
詳細は後述をご覧いただきたいのですが
・ 音楽 : 学生の声で歌うMVの楽曲部分の生成・制作
・ CGモーション: 学生の姿で音楽に合わせて動く3Dモデルおよびモーションの生成・制作
・ モーション動画: 学生の姿で踊る動画の生成およびCGへの実写合成
などが、各構成要素で行っていることです。
インターン上での体験であるため、MVとしての品質以上に、デバイス / 技術 / データ...を多く組み合わせることを意識。例えば、CGアニメーションと動画生成AI+実写合成という異なる技術で、学生のMV上でのモーションを作っていますが、各アプローチのメリット・手間・映像としての見え方の違いなどを、触りながら体験できることを狙いとしています。
また2.5時間で体験が完結するように、事前の開発・制作と、当日実施することを切り分けて進行しました。
詳細は後述をご覧いただきたいのですが
・ 音楽 : 学生の声で歌うMVの楽曲部分の生成・制作
・ CGモーション: 学生の姿で音楽に合わせて動く3Dモデルおよびモーションの生成・制作
・ モーション動画: 学生の姿で踊る動画の生成およびCGへの実写合成
などが、各構成要素で行っていることです。
インターン上での体験であるため、MVとしての品質以上に、デバイス / 技術 / データ...を多く組み合わせることを意識。例えば、CGアニメーションと動画生成AI+実写合成という異なる技術で、学生のMV上でのモーションを作っていますが、各アプローチのメリット・手間・映像としての見え方の違いなどを、触りながら体験できることを狙いとしています。
また2.5時間で体験が完結するように、事前の開発・制作と、当日実施することを切り分けて進行しました。
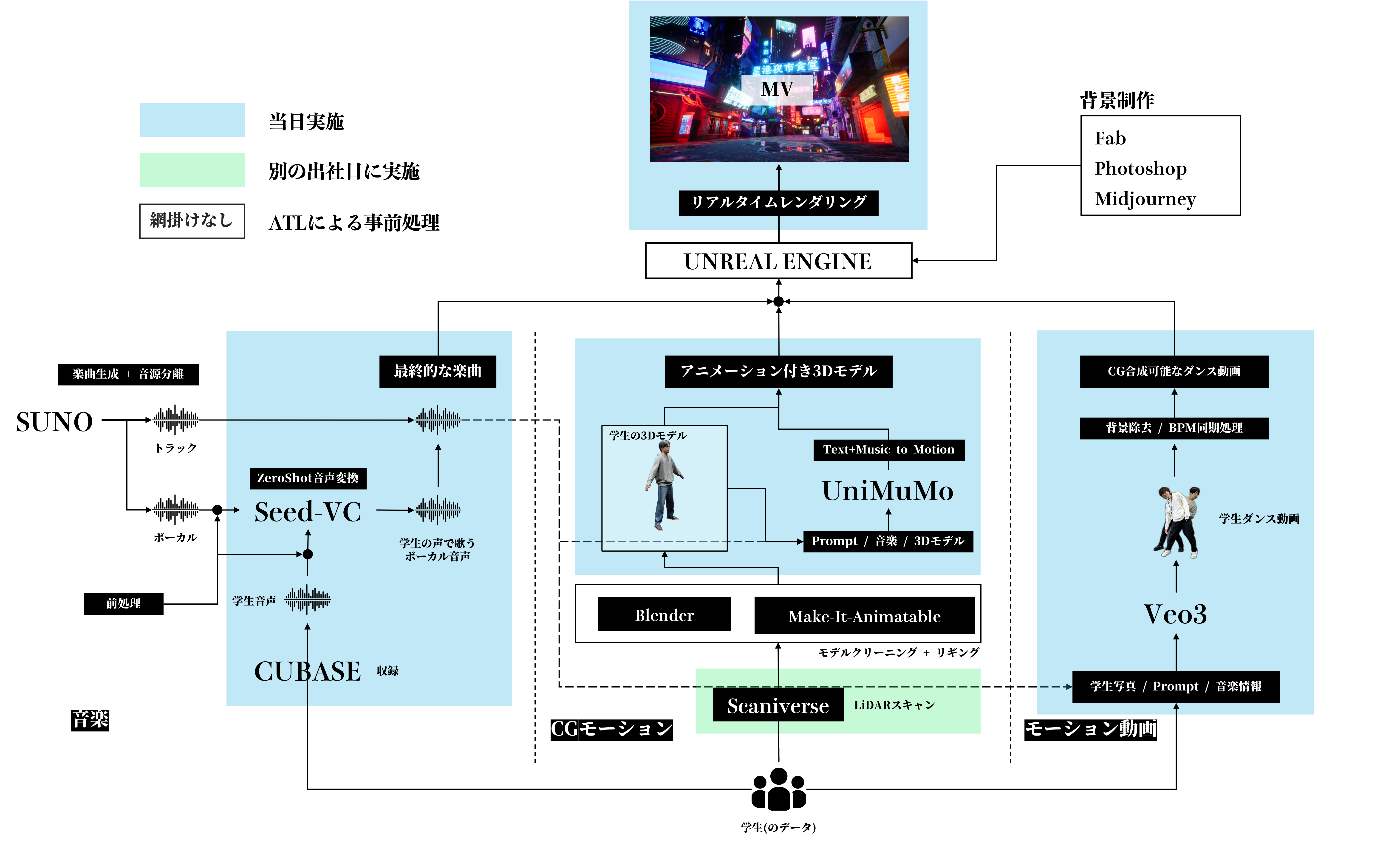
構成や進行の概要
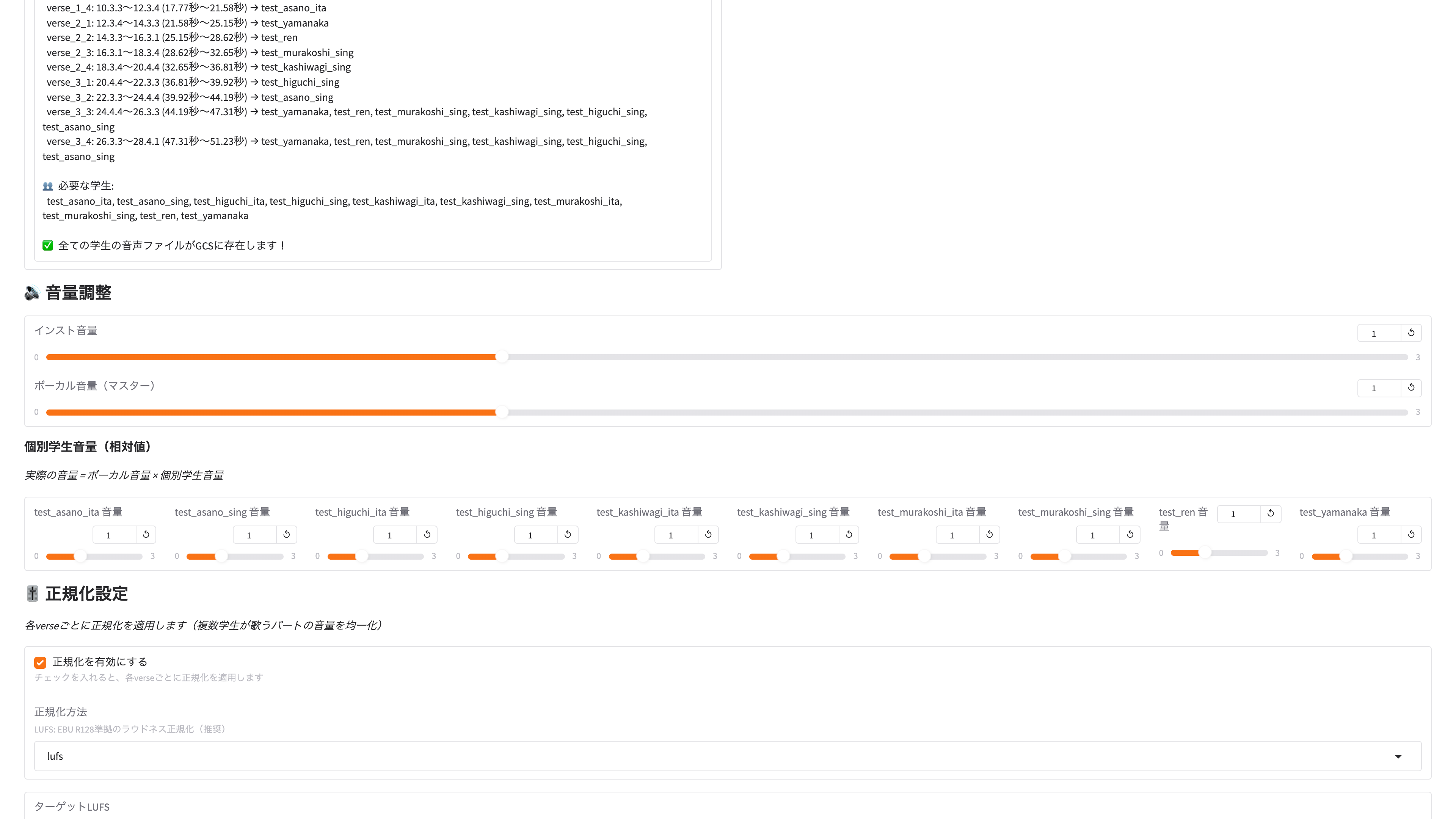
MVを制作する上で、全学生にスポットライトがあたる瞬間を作りたかったので、4小節ごとにパート分け。学生2人で1パート(4小節)を担当とし、担当パートはその学生だけが歌って踊る構成にしました。また最後の4小節は全員パートとし、全学生の声や姿を使いました。
※ (当たり前ですが) あくまで生成AIやCGを使って、学生の歌声やモーションを作ったので、学生に歌ったり踊ったりしてもらったわけではありません。
※ (当たり前ですが) あくまで生成AIやCGを使って、学生の歌声やモーションを作ったので、学生に歌ったり踊ったりしてもらったわけではありません。

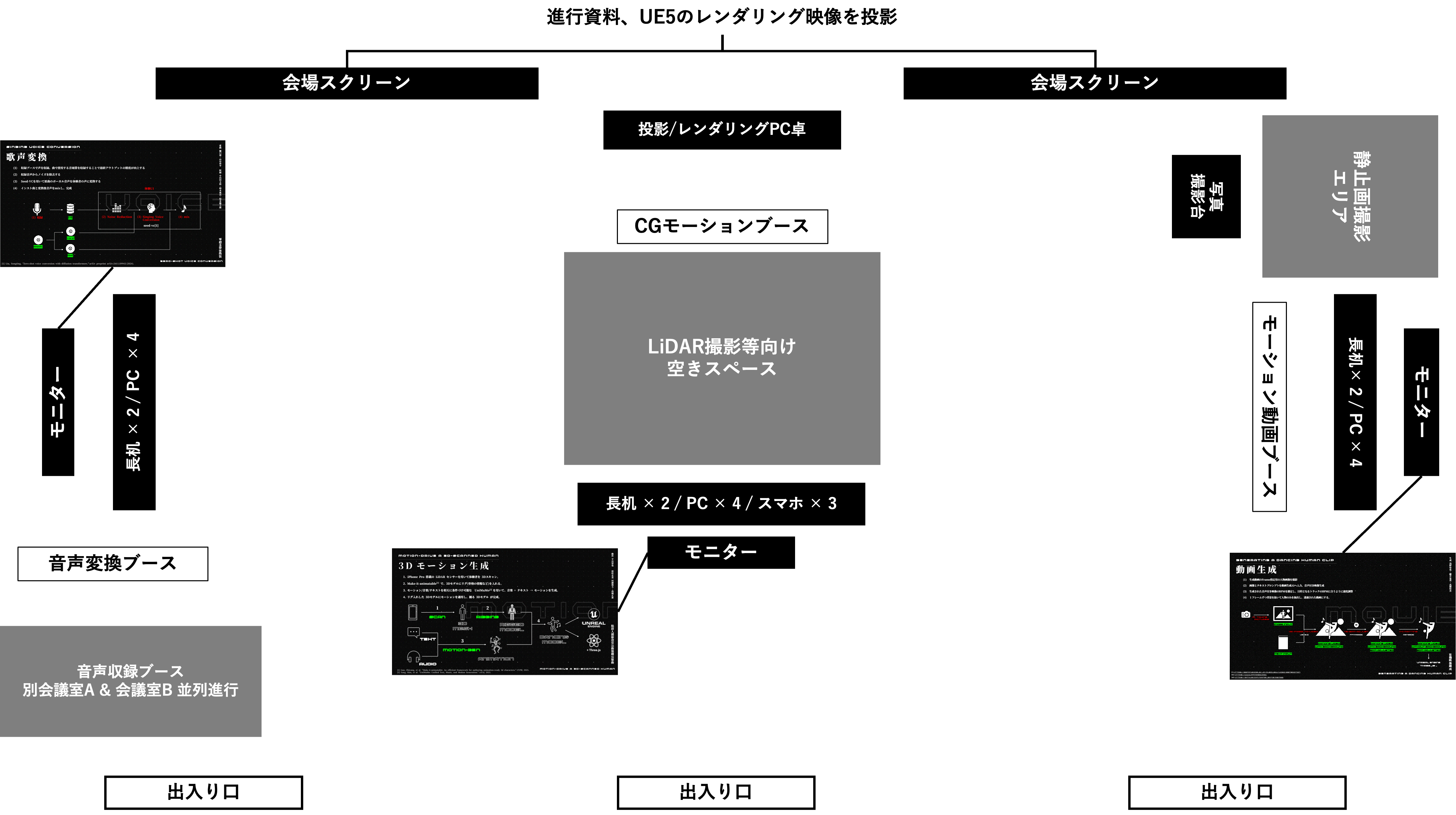
会場は音声変換 / CGモーション生成 / モーション動画生成 の3ブースを大きな会議室に設営。音声収録用にコンデンサーマイクなどをおいた部屋を2つ用意。これらに、グループ分けした学生が並列で順々に回り体験・生成・データ取得などを進行しました。
MVのサンプル
最終的なMVは以下のようなものです。
肖像権などの関係で、インターン参加学生ではなく、ATLメンバーの声や姿で制作したサンプルですが、インターン時と同条件でデータ取得などを行った結果です。
肖像権などの関係で、インターン参加学生ではなく、ATLメンバーの声や姿で制作したサンプルですが、インターン時と同条件でデータ取得などを行った結果です。
以下のように、スキャンしたCGモデルを生成したアニメーションに従い動かすシーンと、生成動画とCGの実写合成シーンが、組み合わさっている点が分かりやすい特徴かなと思います。

CGモデルを動かしたシーン

生成動画を実写合成したシーン
各種技術等の詳細
以下では、各種技術の詳細をご紹介します。検証時の写真などを掲載していますが、人物は全て検証に関わったATLメンバーになります。
音楽パートについて
音楽生成
担当: 小山田圭佑
アプリケーション:Suno(v4.5+)
アプリケーション:Suno(v4.5+)
MVの制作にあたり、元となる楽曲はSunoを活用し生成しました。本インターンおよび体験は夏・冬 2回開催したのですが、楽曲の部分は夏 (2025/07~09あたり) 時点で生成したものを使いました。そのため、v4.5+というバージョンは生成当時の最新Verになります。
・ 楽曲の構成について
制作にあたっては、まず楽曲構成(主に小節数と展開)とBPMを決め、楽曲の時間を決定 (最終的に1.5分前後)。2.5時間の中で作りきれ、最後の視聴時に間延びしないような楽曲を目指しました。
実際にSunoのLyrics欄に入力した歌詞は以下です。よくご存知の方も多いかもしれませんが、歌詞側で以下のような構成を指示すると、おおよそ従ってくれます。
[intro インスト4小節]
[Verse 1]
硝子の雨に濡れた街
二進法で数える呼吸
群れから外れた数字が
君の体温を探してる
[Verse 2]
深海みたいな情報の底
それでも光る真珠がある
仮説という名の朝焼けが
新しい定理を生んでく
[Chorus]
電脳都市の夜が明ける
境界線が溶ける場所で
方程式じゃ解けない
人間という証明を
また、以下のようにprompt内にBPMを記載することで、こちらもおおよそ従ってくれました。
female vocals, city pop, lo-fi, BPM: 130, mellow beats, modern beats, cool vibes, neon, cyberpunk, rage, vocaloid, autotune, dramatic, chill
とはいえ、Chorus(サビ)が2回ループしてしまったりインストに歌声が入ってしまったり、意図した構成にならないこともあるので、promptやハイパーパラメータの調整、Remix機能の利用など、(細かいもの含め)400曲前後の生成を試行錯誤しました。
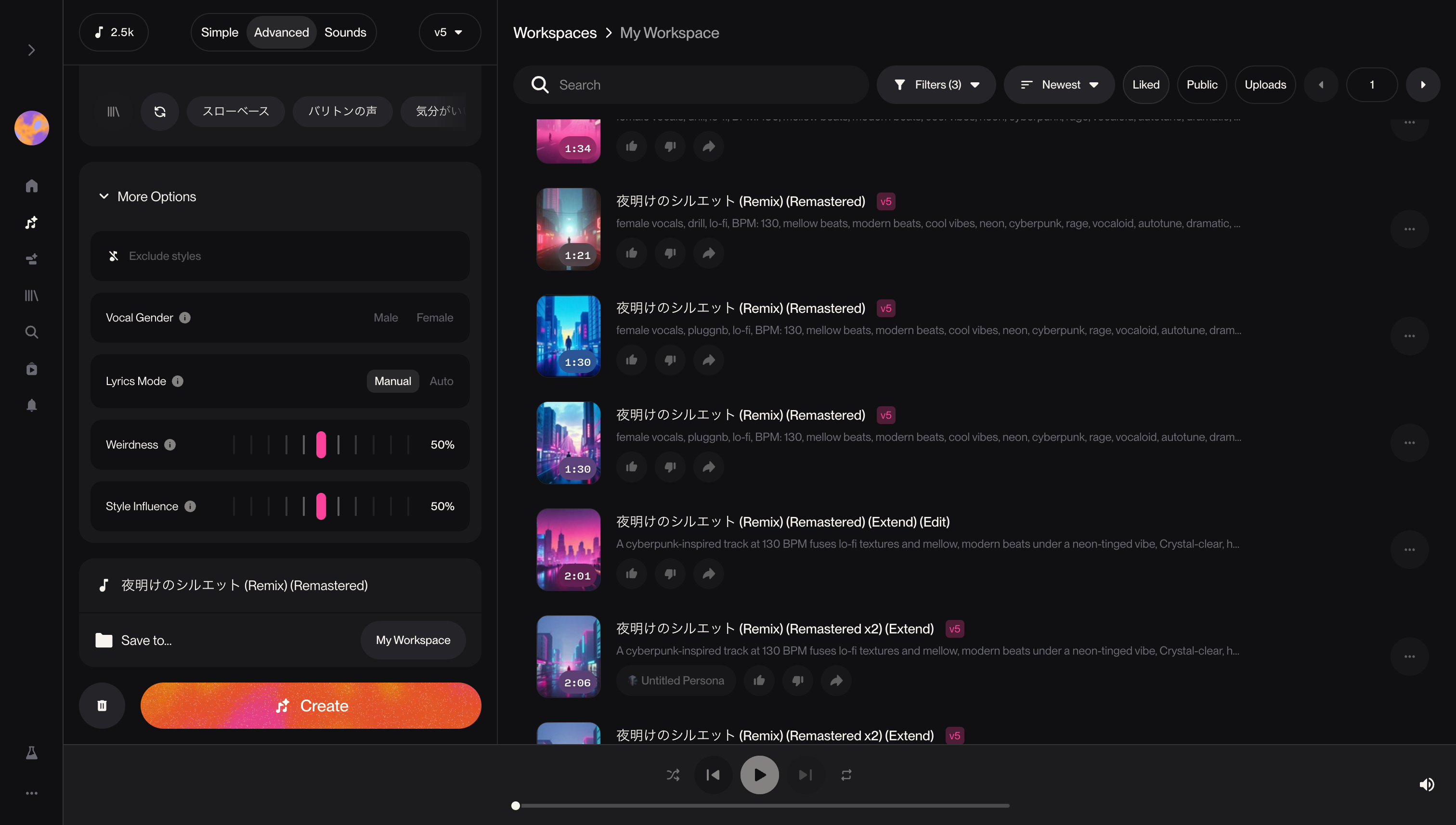
実際にMV制作体験内で使用した生成結果は以下です。
ちなみにprompt内に記載する音楽ジャンル名を変えると、生成される楽曲が大きく変わります。
例えば、以下は、上述したpromptの「city pop」というパートを「Pluggnb 」や「Drill」に差し替えた時の結果です。
(厳密にいうと、以下はv5を使っているので、少し状況は異なります。)
Pluggnb:
Drill:
ということもあり、イメージしている楽曲を言葉などで表現するスキル・知識が豊富な人ほど、うまく使いこなせるのはないかと、作業しながら実感しました。
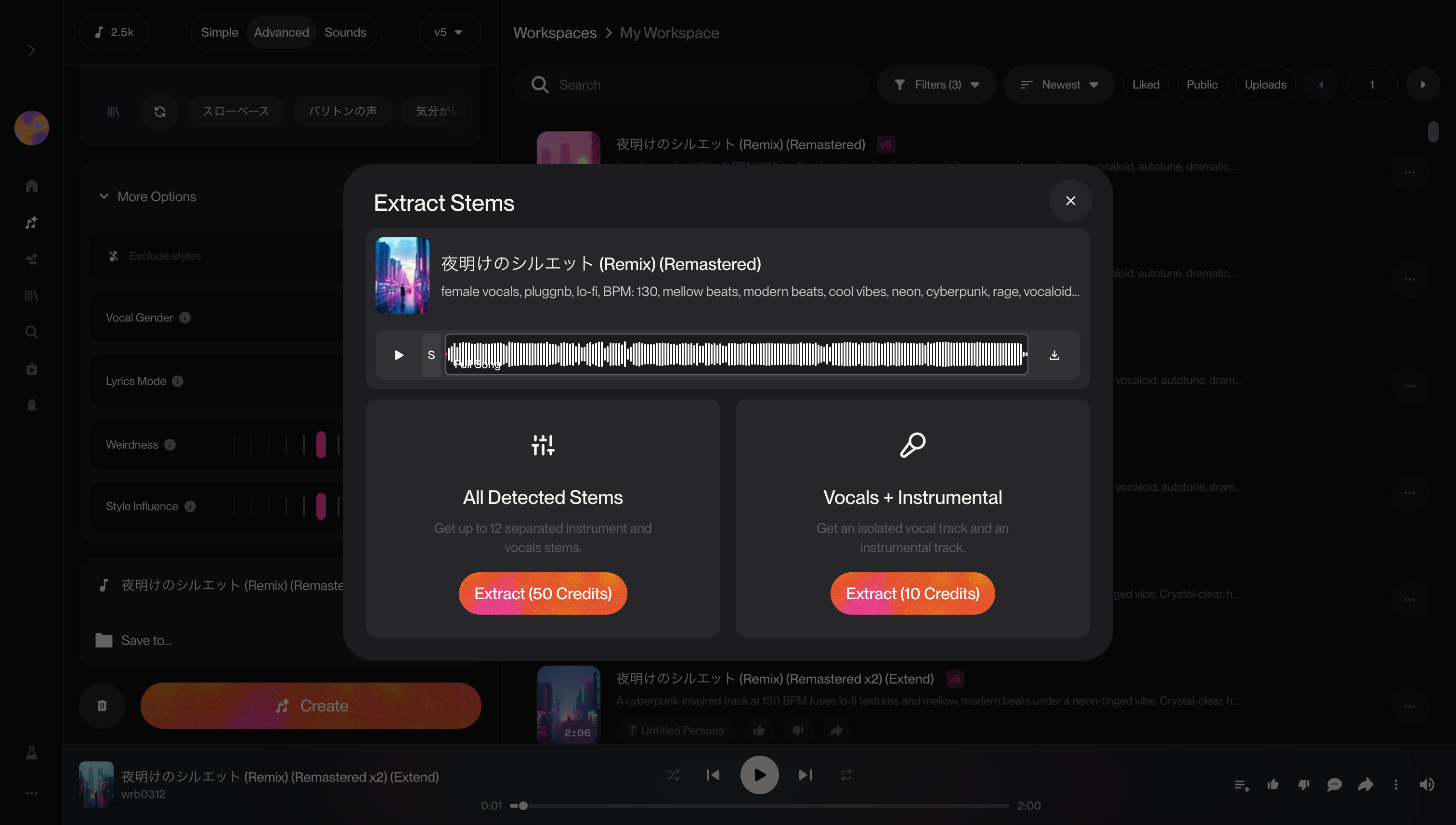
最後に、楽曲をエクスポートする際は「Stems」機能を使いました。これはボーカルと曲を別々にして書き出せる機能です。曲部分は楽器ごとに書き出すことも可能です。後段で音声変換を実施するにあたり、ボーカルだけ / ボーカル抜き のデータが必要のため使用しました。初めは本機能を知らず、オープンソースの音源分離(Demcus )を使っていたのですが、SunoのStems機能で分離した方が高品質な印象でした。
ちなみにprompt内に記載する音楽ジャンル名を変えると、生成される楽曲が大きく変わります。
例えば、以下は、上述したpromptの「city pop」というパートを「Pluggnb 」や「Drill」に差し替えた時の結果です。
(厳密にいうと、以下はv5を使っているので、少し状況は異なります。)
Pluggnb:
Drill:
ということもあり、イメージしている楽曲を言葉などで表現するスキル・知識が豊富な人ほど、うまく使いこなせるのはないかと、作業しながら実感しました。
最後に、楽曲をエクスポートする際は「Stems」機能を使いました。これはボーカルと曲を別々にして書き出せる機能です。曲部分は楽器ごとに書き出すことも可能です。後段で音声変換を実施するにあたり、ボーカルだけ / ボーカル抜き のデータが必要のため使用しました。初めは本機能を知らず、オープンソースの音源分離(Demcus )を使っていたのですが、SunoのStems機能で分離した方が高品質な印象でした。
音声変換
担当: 樋口建
(収録)アプリケーション:Cubase 14
(収録)デバイス : Audio Technica AT4040 (マイク) / Solid State Logic SSL2 (オーディオインターフェース)
(変換)フロントエンド技術スタック:Next.js / Three.js
(変換)デバイス:GCP GCE VM(w/ NVIDIA L4 GPU)
リファレンス:
Seed-VC: https://github.com/Plachtaa/seed-vc
ITAコーパス:https://github.com/mmorise/ita-corpus/tree/main
JVNVコーパス: https://sites.google.com/site/shinnosuketakamichi/research-topics/jvnv_corpus
音声の体験は収録と変換とブースを2つに分けて進行。
(収録)アプリケーション:Cubase 14
(収録)デバイス : Audio Technica AT4040 (マイク) / Solid State Logic SSL2 (オーディオインターフェース)
(変換)フロントエンド技術スタック:Next.js / Three.js
(変換)デバイス:GCP GCE VM(w/ NVIDIA L4 GPU)
リファレンス:
Seed-VC: https://github.com/Plachtaa/seed-vc
ITAコーパス:https://github.com/mmorise/ita-corpus/tree/main
JVNVコーパス: https://sites.google.com/site/shinnosuketakamichi/research-topics/jvnv_corpus
音声の体験は収録と変換とブースを2つに分けて進行。
・ 収録ブース
学生に、音声収録用に確保したブースにてコーパスを読み上げてもらい、声を収録させてもらいました。このとき、ITAコーパス・JVNVコーパス(感情音声コーパス)という2つのコーパスを用意。ITAはナレーションのように淡々と、JVNVは少し感情を込めるように声を張って読んでもらい、性質の異なる音声を収録しました。
ただし、今回はSeed-VCというゼロショット音声変換手法を用いた為、各コーパスの中から10文章程度(1パターンあたり約1分程度)だけ収録しています。
また、Seed-VCでは、ソース音声とターゲット音声という概念があります。変換時には、ソース音声の発話内容や音程(F0保持設定時のみ)を保持しつつ、ターゲット音声の声質で発話する音声が出力されます。
そのため、ソース音声として、Sunoで生成した音楽からボーカルのみを抜き出したアカペラ(およびそれをボーカロイドでカバー)音声を男女3種ずつ事前作成。ターゲット音声としても、上述のように性質の異なる学生音声を2種用意。とすることで、ソースやターゲットを変えることが、変換結果音声にどんな影響を与えるか体験できる構成としました。
ただし、今回はSeed-VCというゼロショット音声変換手法を用いた為、各コーパスの中から10文章程度(1パターンあたり約1分程度)だけ収録しています。
また、Seed-VCでは、ソース音声とターゲット音声という概念があります。変換時には、ソース音声の発話内容や音程(F0保持設定時のみ)を保持しつつ、ターゲット音声の声質で発話する音声が出力されます。
そのため、ソース音声として、Sunoで生成した音楽からボーカルのみを抜き出したアカペラ(およびそれをボーカロイドでカバー)音声を男女3種ずつ事前作成。ターゲット音声としても、上述のように性質の異なる学生音声を2種用意。とすることで、ソースやターゲットを変えることが、変換結果音声にどんな影響を与えるか体験できる構成としました。
・ 音声変換ブース
このブースは、本体験用に開発した以下のようなWebアプリケーションを用いて進行しました。
本アプリケーションはオーディオリアクティブなパーティクル表現を加えるなど、体験をビジュアル面でエンハンスするだけでなく、Seed-VCの各パラメータや与える音声データの違いが及ぼす影響について理解しながら、納得できる結果がでるまで何度もトライし、比較しやすいことを目的に設計しています。
前述したターゲット音源での変換結果の違いについて、ソース音源(原曲アカペラ)を固定し、ターゲット音源として樋口のITA収録、歌声収録で切り替えたときの比較検証を行ってみました。
ITA収録をターゲット音源にした場合の変換結果
歌声収録をターゲット音源にした場合の変換結果
聴き比べてみると、声質が微妙に異なる事がわかると思います。本人所感としては、前者の方は機械音声っぽく、後者の方が自分の歌う時の声に近いと感じます。とはいえ、学生に歌ってもらうというのはハードルが高いと懸念したため、今回はJVNV(感情音声)コーパスを用い、少し張った音声収録も目指す設計にしました。
前述したターゲット音源での変換結果の違いについて、ソース音源(原曲アカペラ)を固定し、ターゲット音源として樋口のITA収録、歌声収録で切り替えたときの比較検証を行ってみました。
ITA収録をターゲット音源にした場合の変換結果
歌声収録をターゲット音源にした場合の変換結果
聴き比べてみると、声質が微妙に異なる事がわかると思います。本人所感としては、前者の方は機械音声っぽく、後者の方が自分の歌う時の声に近いと感じます。とはいえ、学生に歌ってもらうというのはハードルが高いと懸念したため、今回はJVNV(感情音声)コーパスを用い、少し張った音声収録も目指す設計にしました。
収録ブース・変換ブース・UE5でのレンダリング卓の連携をスムーズにする為、各種音声データが自動でストレージにアップロードする仕組みや、それらをミキシングできる管理者用音声ミックスウェブアプリも開発。リアルタイムな体験進行を意識しました。
CGモーション パートについて
LiDARと3DGSについて
担当 : 村越海斗
アプリケーション :Scaniverse,Blender
デバイス : iPhone 16 Pro, GCP GCE VM(w/ NVIDIA L4 GPU)
リファレンス:
MILo:https://github.com/Anttwo/MILo
COLMAP:https://github.com/colmap/colmap
Instant Skinned Gaussian Avatars:https://github.com/naruya/gaussian-vrm
本章では、人物の3Dモデル作成手法について説明します。スキャン手法として、LiDARセンサーを活用した手法と、3Dガウシアンプラッティング(3DGS)を用いた手法を比較・検討しました。
1) LiDARによる検証
LiDAR(Light Detection and Ranging)スキャンはレーザー光の反射を利用して対象物との距離を測定する技術です。今回は、Niantic社が提供している3Dスキャンアプリ「Scaniverse」を使用しました。Scaniverseで「メッシュ」モードを選択することでLiDARによるスキャンが可能です。学生に被写体となってもらい、撮影を行いました。後工程のリギングをスムーズに行うために、Aポーズの状態でスキャンしました。
アプリケーション :Scaniverse,Blender
デバイス : iPhone 16 Pro, GCP GCE VM(w/ NVIDIA L4 GPU)
リファレンス:
MILo:https://github.com/Anttwo/MILo
COLMAP:https://github.com/colmap/colmap
Instant Skinned Gaussian Avatars:https://github.com/naruya/gaussian-vrm
本章では、人物の3Dモデル作成手法について説明します。スキャン手法として、LiDARセンサーを活用した手法と、3Dガウシアンプラッティング(3DGS)を用いた手法を比較・検討しました。
1) LiDARによる検証
LiDAR(Light Detection and Ranging)スキャンはレーザー光の反射を利用して対象物との距離を測定する技術です。今回は、Niantic社が提供している3Dスキャンアプリ「Scaniverse」を使用しました。Scaniverseで「メッシュ」モードを選択することでLiDARによるスキャンが可能です。学生に被写体となってもらい、撮影を行いました。後工程のリギングをスムーズに行うために、Aポーズの状態でスキャンしました。

当初はTポーズも検討しましたが、モーションを付与した際に肩周りのメッシュに違和感が生じたため、より自然な動きが可能なAポーズを採用しています。撮影のコツとして、均一な光が当たる空間で、被写体の周囲をゆっくりと2~3周することで綺麗にスキャンすることができました。被写体が人間であるため、完全に静止している物体とは異なり、わずかに動いてしまうことがあります。そのため、悪い意味で慎重になり撮影時間を伸ばしてしまうと、テクスチャにズレが生じ、目の位置が合わなくなるなどの問題が生じやすくなります。実験を重ねた結果、2~3周程度が最適という判断に至りました。実際にLiDARで作成した3Dモデルは下記です。

2) 3DGSによる検証
LiDARセンサーを使用せずに画像から高精細な3D空間を再構築する手法として、3DGSも検討しました。Scaniverseで「Splat」モードを選択することで、3DGSスキャンができます。
LiDARセンサーを使用せずに画像から高精細な3D空間を再構築する手法として、3DGSも検討しました。Scaniverseで「Splat」モードを選択することで、3DGSスキャンができます。

上の3DGSと、LiDARスキャンによる3Dモデルを比べると、LiDARスキャンモデルでは、体の一部に凸凹が現れてしまったり、ゴツゴツな質感に見える一方で、3DGSでは写真に近い(実物に近い)質感に見えると思います。なので、よりリアルに近い3DGSを使いたかったのですが、3DGSにダンスなどのアニメーションさせることは容易ではありません。そのため、GSとメッシュを同時に生成する「MILo」と、GSをメッシュに追従させる大阪・関西万博2025のシグネチャーパビリオン「nulll²ヌルヌル)」で使用された「Instant Skinned Gaussian Avatars」の2つの手法を試しました。
2.1) MILo
3DGSを生成しながら、同時に3Dメッシュも再構築する手法である「MILo」を試しました。3DGSを生成するため、メッシュにも3DGSの質感が反映されると考えたためです。前処理として、学生の周囲を動画で撮影し、数フレームごとに画像を切り出しました。その後、それらの多視点画像を用いて「COLMAP」でカメラパラメータを計算し、MILoに入力しました。
期待していたほどテクスチャが鮮明ではなく、LiDARスキャンによる3Dモデルのほうが鮮明であったため、今回は不十分であると判断しました。
2.1) MILo
3DGSを生成しながら、同時に3Dメッシュも再構築する手法である「MILo」を試しました。3DGSを生成するため、メッシュにも3DGSの質感が反映されると考えたためです。前処理として、学生の周囲を動画で撮影し、数フレームごとに画像を切り出しました。その後、それらの多視点画像を用いて「COLMAP」でカメラパラメータを計算し、MILoに入力しました。
期待していたほどテクスチャが鮮明ではなく、LiDARスキャンによる3Dモデルのほうが鮮明であったため、今回は不十分であると判断しました。

2.2) Instant Skinned Gaussian Avatars
次に、3DGSのデータ(.plyファイル)を動かす「Instant Skinned Gaussian Avatars」を試しました。下記の画像はplyファイルをインポートした際のモデルです。このような3DGS特有の質感を維持したまま、アニメーションさせることができるため、品質は十分でした。しかし、今回はWeb上ではなくUE5上でモデルを動かす必要がありました。既存のライブラリを使うことができず、UE5のためにシステムを0から構築する必要があったため工数の観点から断念しました。
次に、3DGSのデータ(.plyファイル)を動かす「Instant Skinned Gaussian Avatars」を試しました。下記の画像はplyファイルをインポートした際のモデルです。このような3DGS特有の質感を維持したまま、アニメーションさせることができるため、品質は十分でした。しかし、今回はWeb上ではなくUE5上でモデルを動かす必要がありました。既存のライブラリを使うことができず、UE5のためにシステムを0から構築する必要があったため工数の観点から断念しました。

以上の比較・検証の結果、LiDARでスキャンしたモデルを使用することにしました。
モーション生成
担当: 平川智也
アプリケーション : Python(Make-It-Animatable, UniMuMo), TypeScript(React, Three.js),
デバイス : Local PC(MacBook Pro; Frontend), GCP GCE VM(w/ NVIDIA L4 GPU; Backend)・
リファレンス:
Make-It-Animatable:https://jasongzy.github.io/Make-It-Animatable/
UniMuMo:https://hanyangclarence.github.io/unimumo_demo/
hy-motion-fbx-exporter:https://github.com/zysilm-ai/hy-motion-fbx-exporter
ComfyUI-HyMotion:https://github.com/Aero-Ex/ComfyUI-HyMotion
アプリケーション : Python(Make-It-Animatable, UniMuMo), TypeScript(React, Three.js),
デバイス : Local PC(MacBook Pro; Frontend), GCP GCE VM(w/ NVIDIA L4 GPU; Backend)・
リファレンス:
Make-It-Animatable:https://jasongzy.github.io/Make-It-Animatable/
UniMuMo:https://hanyangclarence.github.io/unimumo_demo/
hy-motion-fbx-exporter:https://github.com/zysilm-ai/hy-motion-fbx-exporter
ComfyUI-HyMotion:https://github.com/Aero-Ex/ComfyUI-HyMotion
本章では前章で述べた、LiDARスキャンした学生の3Dモデルに対するモーション生成について説明します。今回は、動きに関する指示表現テキスト / 学生担当パートの音楽 / 学生の3Dモデルを入力すると、音に合わせて動くモーションが生成できるようにしました。ターミナルをモチーフにしたサイバー感を感じさせるUIを作成し、3Dモデルを色々な角度から観察しながら、テキストを変化させ、MVに使用するモーションを生成してもらいました。

技術的要素として大きく(1)Make-It-Animatableによる自動リギング・スキニング (2)UniMuMoによる(Text+Music)-to-Motion の2つがあります。
(1) Make-It-Animatable による自動リギング・スキニング
LiDARスキャンし、Blenderなどで不要な部分を除去した3Dモデルに対して、リギングを行います。 Make-It-Animatable では、3Dモデルを入力するとスキニング・リギングなどを自動で実行できます。今回は同モデルを使用して全員分のリギングを前処理として行いました。
(2) UniMuMo による(Text+Music)-to-Motion
リギングしたモデルに対してモーションを生成する手法として、UniMuMo を採用しました。この手法では、音楽とモーション、テキストを同じ空間に埋め込むことで、クロスドメインでの条件付のもとでの生成を可能にします。今回は音楽とテキストで条件付けしたもとで、モーションの生成を行います。あまり音楽を加味できるモーション生成は多くなく、ちゃんと音楽(のリズムやBPM)にあった動き(ダンス)を生成したかったので採用しました。
補足ですが、生成されるモーションはSMPLに準拠したもので、これをMake-It-Animatableでリギングした3Dモデルに適用するためには別途ボーンのマッピングやデータ形式の変換が必要になります。実はここが一番大変だったのですが…、自動化できる仕組みを開発しました。
(1) Make-It-Animatable による自動リギング・スキニング
LiDARスキャンし、Blenderなどで不要な部分を除去した3Dモデルに対して、リギングを行います。 Make-It-Animatable では、3Dモデルを入力するとスキニング・リギングなどを自動で実行できます。今回は同モデルを使用して全員分のリギングを前処理として行いました。
(2) UniMuMo による(Text+Music)-to-Motion
リギングしたモデルに対してモーションを生成する手法として、UniMuMo を採用しました。この手法では、音楽とモーション、テキストを同じ空間に埋め込むことで、クロスドメインでの条件付のもとでの生成を可能にします。今回は音楽とテキストで条件付けしたもとで、モーションの生成を行います。あまり音楽を加味できるモーション生成は多くなく、ちゃんと音楽(のリズムやBPM)にあった動き(ダンス)を生成したかったので採用しました。
補足ですが、生成されるモーションはSMPLに準拠したもので、これをMake-It-Animatableでリギングした3Dモデルに適用するためには別途ボーンのマッピングやデータ形式の変換が必要になります。実はここが一番大変だったのですが…、自動化できる仕組みを開発しました。
UniMuMoの公開モデルは、出力されるモーションのクオリティが、学習に用いたデータセットに依存しており、入力テキストによって大きく変わりました。そのため、UniMuMoのGithubレポジトリや学習に使用されたデータセットのHPを参照しながら学生とともに探りながらモーションを生成する形になりました。
また、すでに述べましたが、UniMuMoで生成されるSMPL準拠のモーションをMake-It-Animatableで出力される、Mixamoのリグに対応させるのは一工夫必要でした。UnrealEngine との入出力にも影響が出るため、事前にUnrealEngine で実作業を行う小山田と入念にモーション生成や変換の実証実験を行いました。
※2026年1月(本実験後)に公開されたhy-motion-fbx-exporterやComfyUI-HyMotionではSMPL形式のモーションからMixamo形式への変換が簡単にできるようになっています。この実験でも試してみる価値がありそうです。
また、すでに述べましたが、UniMuMoで生成されるSMPL準拠のモーションをMake-It-Animatableで出力される、Mixamoのリグに対応させるのは一工夫必要でした。UnrealEngine との入出力にも影響が出るため、事前にUnrealEngine で実作業を行う小山田と入念にモーション生成や変換の実証実験を行いました。
※2026年1月(本実験後)に公開されたhy-motion-fbx-exporterやComfyUI-HyMotionではSMPL形式のモーションからMixamo形式への変換が簡単にできるようになっています。この実験でも試してみる価値がありそうです。
モーション動画パートについて
本章では、実写合成の元となる学生のモーション動画生成について説明します。
今回のMV制作においては、「ダンスのクオリティ」と「学生による制作体験」という制約を踏まえて、特に以下の4つの観点から技術検証を行いました。
・ ダンスジャンルらしさ:プロンプトで指定したダンスジャンルらしく踊ってくれるか
・ 生成速度:限られた体験時間内で十分なプロンプトの試行錯誤ができるだけの高速な生成が可能か
・ 楽曲との同期性:楽曲のリズムやBPMに合った、違和感のない動きを生成できるか
・ 画角の制御性:生成動画をUnreal Engine上で実写合成する上で、身体の見切れが発生しない構図を維持できるか
これらの観点に基づき、モデルの選定、動画のリズム感に関する後処理、体が見切れないような事前撮影、UI設計の4点について、説明します。
今回のMV制作においては、「ダンスのクオリティ」と「学生による制作体験」という制約を踏まえて、特に以下の4つの観点から技術検証を行いました。
・ ダンスジャンルらしさ:プロンプトで指定したダンスジャンルらしく踊ってくれるか
・ 生成速度:限られた体験時間内で十分なプロンプトの試行錯誤ができるだけの高速な生成が可能か
・ 楽曲との同期性:楽曲のリズムやBPMに合った、違和感のない動きを生成できるか
・ 画角の制御性:生成動画をUnreal Engine上で実写合成する上で、身体の見切れが発生しない構図を維持できるか
これらの観点に基づき、モデルの選定、動画のリズム感に関する後処理、体が見切れないような事前撮影、UI設計の4点について、説明します。
A. 動画生成AIモデルの選定
ダンスにはハウス、ロック、ブレイキンなど多様なジャンルが存在しますが、各動画生成AIモデルがそれぞれのジャンル名と振付の対応関係をどの程度学習しているかについては明らかではありません。そこで今回は、ジャンル名のみを簡潔に指定したプロンプトを用いて、5つのモデル(Runway Gen-4, Veo 3.1, Kling 2.1, Wan 2.5, Sora2)で実験を行いました。
合わせて、動画生成AIの基本的な性能(プロンプトによる制御性や動きの自然さ)や生成の即時性についても評価し、総合的に比較検討を行いました。
合わせて、動画生成AIの基本的な性能(プロンプトによる制御性や動きの自然さ)や生成の即時性についても評価し、総合的に比較検討を行いました。
その中でも本稿時点でVeo 3.1は、生成時間が約1〜2分と比較的長いものの、5モデルの中で最も動きが自然であり、指定したジャンルの特徴をある程度反映していることが確認できました。これらの点を総合的に評価し、採用モデルとして選定しました。
また、Veo 3.1の特徴として、タイムラインプロンプティング機能を備えている点が挙げられます。タイムラインプロンプティングとは、「動画開始1秒から2秒の間で立ち上がる」といったように、一本の動画を短い区間に分割し、区間ごとに個別の動作を指定できる機能です。この機能を使用することにより、「同一の振付を複数回繰り返す」「振付が終わり次第静止する」といった動画生成AIの傾向を抑制し、振付にバリエーションを持たせることができると考えました。
また、Veo 3.1の特徴として、タイムラインプロンプティング機能を備えている点が挙げられます。タイムラインプロンプティングとは、「動画開始1秒から2秒の間で立ち上がる」といったように、一本の動画を短い区間に分割し、区間ごとに個別の動作を指定できる機能です。この機能を使用することにより、「同一の振付を複数回繰り返す」「振付が終わり次第静止する」といった動画生成AIの傾向を抑制し、振付にバリエーションを持たせることができると考えました。
B. 動画のリズム感に関する後処理
Veo 3.1にはサウンドを入力する機能がないため、手元の楽曲(のBPMやリズム)と生成される動画内の動きを同期させる、ということは単純には不可能です。
一方で、Veo3.1は映像と一緒に音も生成されます。そこで以下のような手順で、生成音源の情報を利用して、手元の音楽と生成映像の動きのリズム感を同期させるようにしました。
1. プロンプトに「ダンスミュージックを生成する」ことを明記し、必ずBPMを計測しやすいような音源と映像のセットを出力させる(※実例は後述)
2. FFmpegライブラリを用いて生成音源のBPMを測定
3. 生成音源のBPMを基準として、本体験で使用する楽曲のBPM(130)に一致するよう動画の再生速度を調整
これらの手順により、体験用音楽のリズムに同期して被写体がダンスしているように見せることができるようになりました。
以下は、1.のプロンプト調整を行う前に生成された、BPMを計測できない音源付きで生成された動画の例です。
一方で、Veo3.1は映像と一緒に音も生成されます。そこで以下のような手順で、生成音源の情報を利用して、手元の音楽と生成映像の動きのリズム感を同期させるようにしました。
1. プロンプトに「ダンスミュージックを生成する」ことを明記し、必ずBPMを計測しやすいような音源と映像のセットを出力させる(※実例は後述)
2. FFmpegライブラリを用いて生成音源のBPMを測定
3. 生成音源のBPMを基準として、本体験で使用する楽曲のBPM(130)に一致するよう動画の再生速度を調整
これらの手順により、体験用音楽のリズムに同期して被写体がダンスしているように見せることができるようになりました。
以下は、1.のプロンプト調整を行う前に生成された、BPMを計測できない音源付きで生成された動画の例です。
プロンプト調整を行うことで、以下のように、BPMの後処理が可能なリズム感のある動画を生成できるようになりました。
C. 体が見切れないような事前撮影
生成される動画の途中で手足が見切れてしまうことを防ぐため、動画生成AIに入力する学生の静止画(スタートフレーム / エンドフレーム)を撮影するブースなども工夫しました。
実験した結果、フレームアウトのリスクは、入力画像時点で左右上下の余白を十分に確保することで低減することができそうでした。そのため、カメラの画角内に収まる範囲を養生テープでマーキングし、被写体の学生がポージングできる範囲を把握しやすくする工夫を行いました。
もちろん、プロンプトなどで見切れるほどの激しい動きはしないようにさせるなどの指示も必要かとは思われます。
実験した結果、フレームアウトのリスクは、入力画像時点で左右上下の余白を十分に確保することで低減することができそうでした。そのため、カメラの画角内に収まる範囲を養生テープでマーキングし、被写体の学生がポージングできる範囲を把握しやすくする工夫を行いました。
もちろん、プロンプトなどで見切れるほどの激しい動きはしないようにさせるなどの指示も必要かとは思われます。

D. UIの設計
当日、学生にスムーズな体験を提供するため、入力画像の選択、プロンプト作成、BPM調整、背景透過といった一連のフローが単一画面で完結するWebアプリケーションも開発しました。
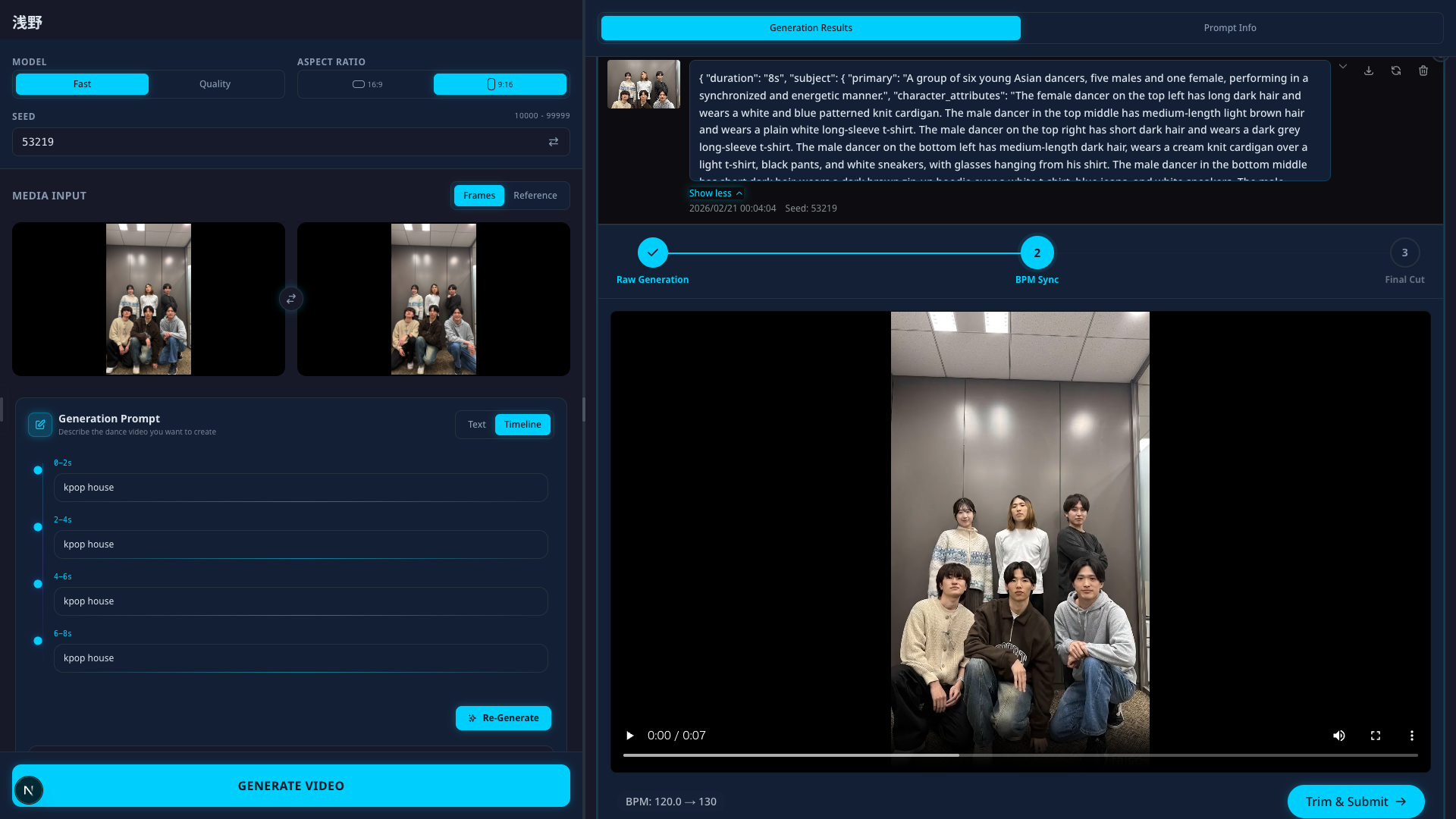
参加学生の動画生成に関する習熟度が事前に把握できなかったため、制作フローで負担が大きくなり得る工程を重点的に支援する設計を行いました。
特にプロンプト作成について考えると、よほどダンスに興味関心のある学生でないと、いきなり英語で細かく動きなどについて指示を与えることを困難だと思います。そのため、ダンスジャンルや簡単な動作を入力するだけで、先述したプロンプトの工夫を反映したVeo 3.1のタイムラインプロンプトを自動生成するエージェントを作成。Webアプリケーションから簡単にエージェントを扱えるようにしました。
特にプロンプト作成について考えると、よほどダンスに興味関心のある学生でないと、いきなり英語で細かく動きなどについて指示を与えることを困難だと思います。そのため、ダンスジャンルや簡単な動作を入力するだけで、先述したプロンプトの工夫を反映したVeo 3.1のタイムラインプロンプトを自動生成するエージェントを作成。Webアプリケーションから簡単にエージェントを扱えるようにしました。
背景制作やUE5と各種データの連携について
担当: 小山田圭佑
アプリケーション : UnrealEngine 5.3, Midjourney, Photoshop, Fab
デバイス : Windows PC + NVIDIA RTX A6000 GPU
2.5時間の中で、データ取得や様々な生成だけでなく、MVとして視聴する部分までを実施するため、リアルタイムレンダリングが可能な Unreal Engine 5(UE5)を採用しました。ここでは、UE5上での背景制作や、上述したような生成・変換データとの連携について考えます。
アプリケーション : UnrealEngine 5.3, Midjourney, Photoshop, Fab
デバイス : Windows PC + NVIDIA RTX A6000 GPU
2.5時間の中で、データ取得や様々な生成だけでなく、MVとして視聴する部分までを実施するため、リアルタイムレンダリングが可能な Unreal Engine 5(UE5)を採用しました。ここでは、UE5上での背景制作や、上述したような生成・変換データとの連携について考えます。
背景制作について
UE5上で映像を制作するにあたり、主にFabで購入した建造物のアセットなどを活用し背景を制作しました。ある程度の価格のものであれば、ディティールがしっかりしていて、寄りで撮っても綺麗な建物などが購入できました。
一方で、今回はサイバーパンク系統の世界観を作ろうと考えたのですが、そういった世界を分かりやすく象徴するような「漢字で書かれたネオン看板」や「着物を着た人物の屋外看板」などのアセットは入手が簡単ではありませんでした。
例えば「電気屋」と大きく書かれた看板などは公開されていましたが、少し日本人からするとシュールさを感じてしまうと思ったので、適当な造語が書かれた看板を自作しました。
ただ、看板を寄りで撮ることはしないので、引きで撮影された時に、それらしく見えればいいという前提で、文字ベースの看板はPhotoshop、人物が映るような看板はMidJourneyを使い画像素材を制作。UE5上で板ポリに貼り付け、マテリアルを少し調整し、背景要素として使用しています。
一方で、今回はサイバーパンク系統の世界観を作ろうと考えたのですが、そういった世界を分かりやすく象徴するような「漢字で書かれたネオン看板」や「着物を着た人物の屋外看板」などのアセットは入手が簡単ではありませんでした。
例えば「電気屋」と大きく書かれた看板などは公開されていましたが、少し日本人からするとシュールさを感じてしまうと思ったので、適当な造語が書かれた看板を自作しました。
ただ、看板を寄りで撮ることはしないので、引きで撮影された時に、それらしく見えればいいという前提で、文字ベースの看板はPhotoshop、人物が映るような看板はMidJourneyを使い画像素材を制作。UE5上で板ポリに貼り付け、マテリアルを少し調整し、背景要素として使用しています。
・文字がメインの看板
例えば、以下のような看板を制作しました。

こういった文字がメインの看板は、Photoshop上で、テキストの縁のみVer / テクスチャを使って塗ったVer の素材を作成し、PNGで書き出します。

上記画像をテクスチャとする板ポリをUE5上で作成。看板の縁や背面などのメッシュと組み合わせることで、看板のように見せています。
上記の看板を分かりやすく分解すると、以下のようになっています。
上記の看板を分かりやすく分解すると、以下のようになっています。

他にもいくつか看板を作りましたが、それらをシーン上に取り込むと以下のように見えます。
手間が少ない割には、それらしくなったかなと思います。
手間が少ない割には、それらしくなったかなと思います。

・人物が映るような看板
こちらは、例えば以下のシーンで中央に見えている看板などが該当します。

これらはMidjourneyで画像素材を生成し、UE5上で板ポリに貼り付ける形で作成しました。実際に生成した画像は以下です。

UE5側では、以下のようなシンプルなマテリアル設定だけを行い、上記のような看板を作っています。
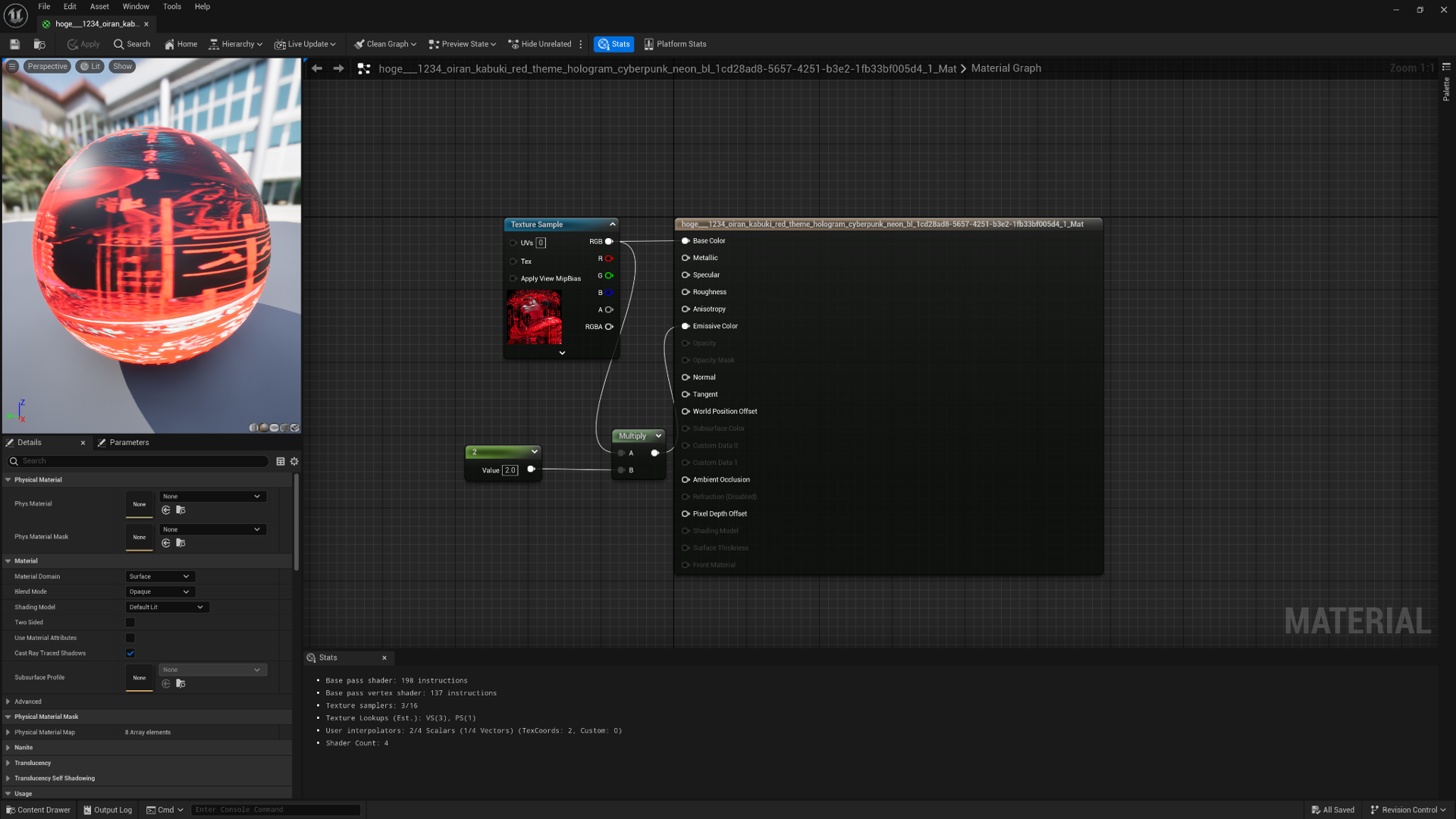
ちなみに背景が黒ければ、MaterialのBlendModeを「Additive」にし、Texture SampleをEmmisiveColorにだけ繋ぐと、少しホログラム感のある看板を作ることもできました。
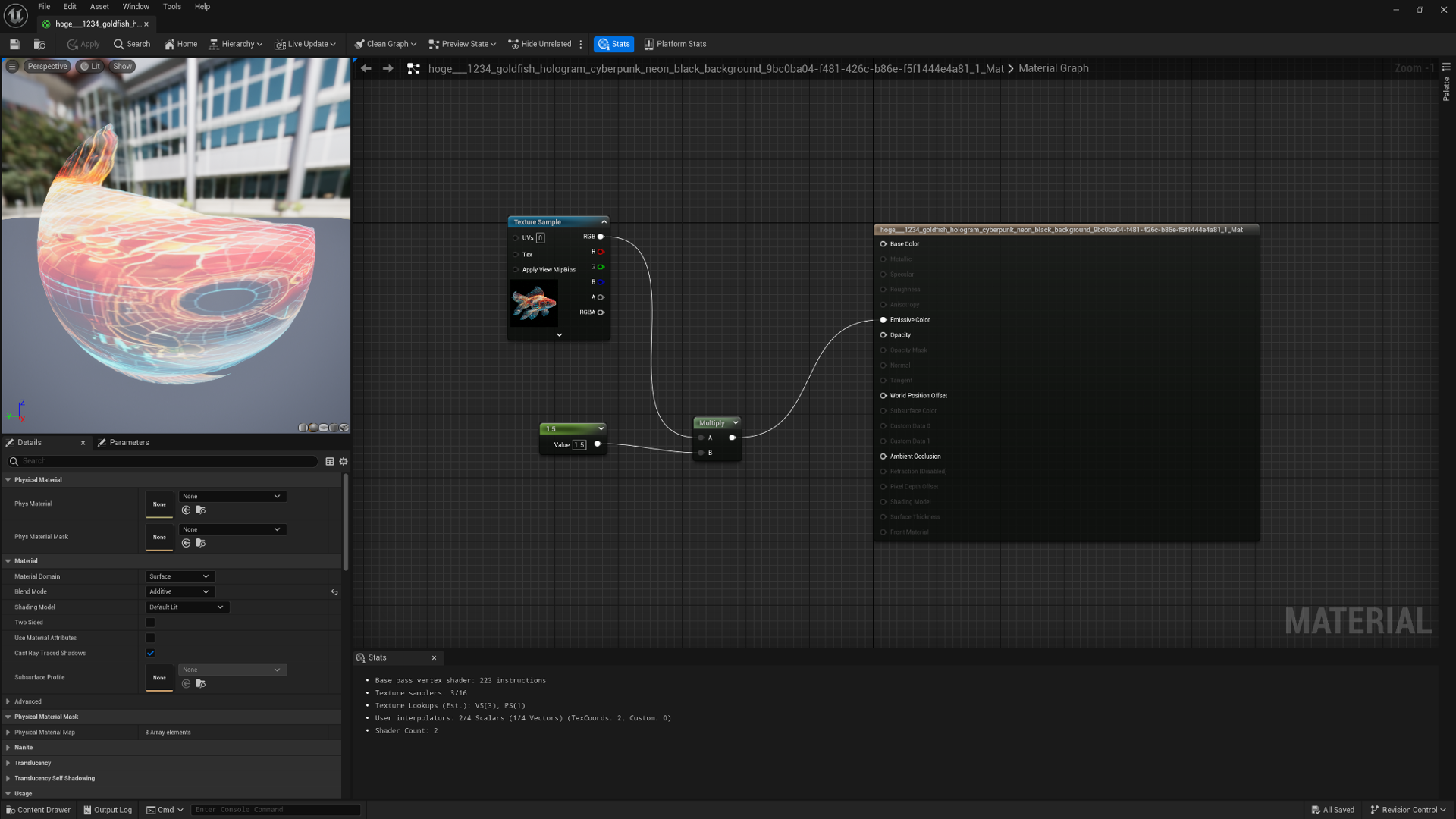

各種データとUE5の連携について
2.5時間という体験の中で完結させるため、UE5シーン上のどこに学生モデルを配置し、どのように撮影するかは、事前にレベルシーケンス機能を使い、タイムライン化しておきました。また当日順次生成されてくる素材を効率的にUE5に取り込むため、ブループリント機能などを使い、学生モデルや、それにアタッチするアニメーション(モーション)などを現場で変更しやすくしておきました。
以下では、データごとに簡単に実施した内容を見ていきます。
以下では、データごとに簡単に実施した内容を見ていきます。
・音楽データについて
今回、MVで流す音楽はレベルシーケンス上に設定しておき、シーケンスを再生するとそれに合わせて音が流れるようにしています。
そのため、学生歌声Verの音楽データを流す際も、レベルシーケンス上の素材を切り替えるだけで対応できました。
そのため、学生歌声Verの音楽データを流す際も、レベルシーケンス上の素材を切り替えるだけで対応できました。
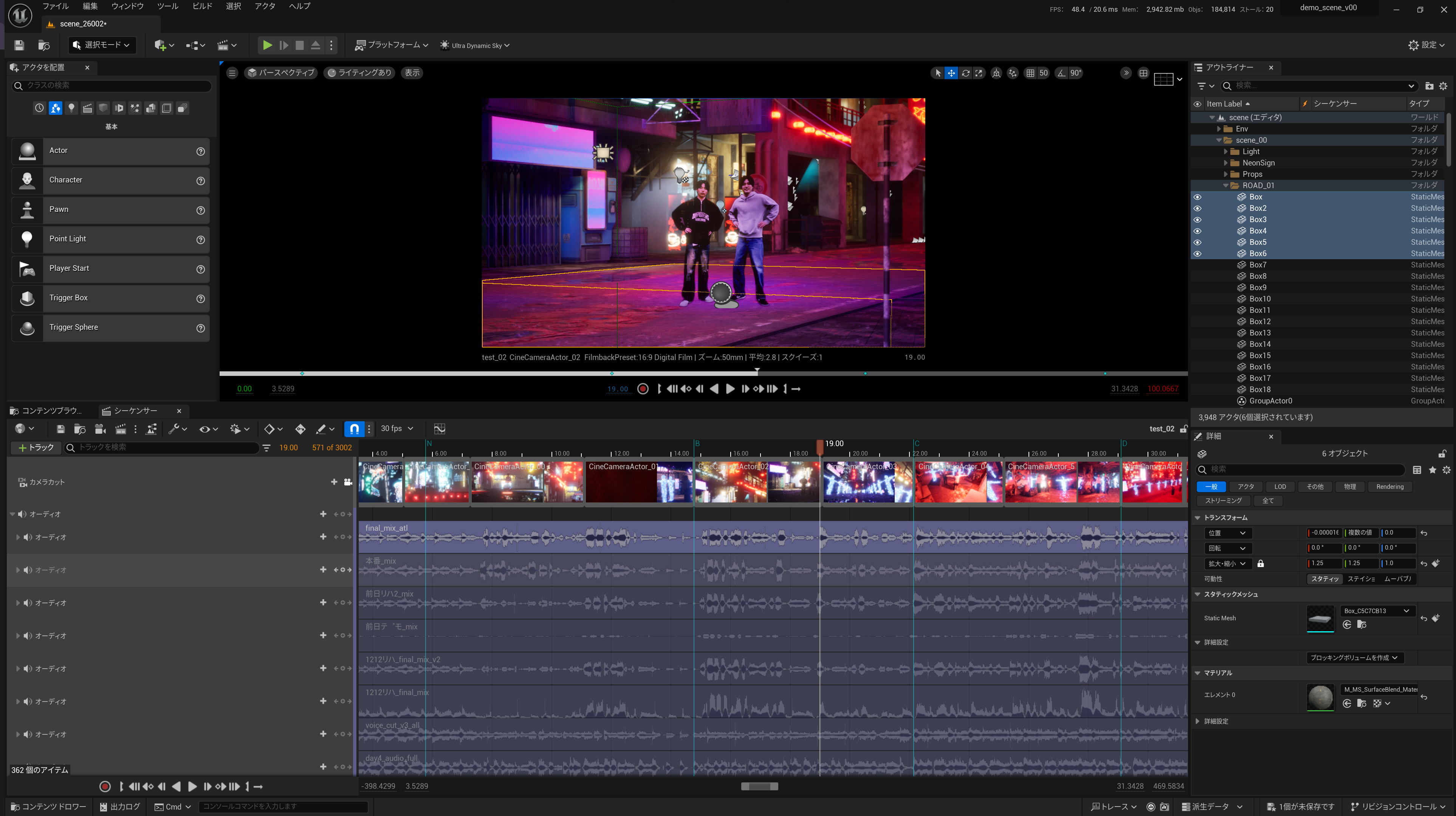
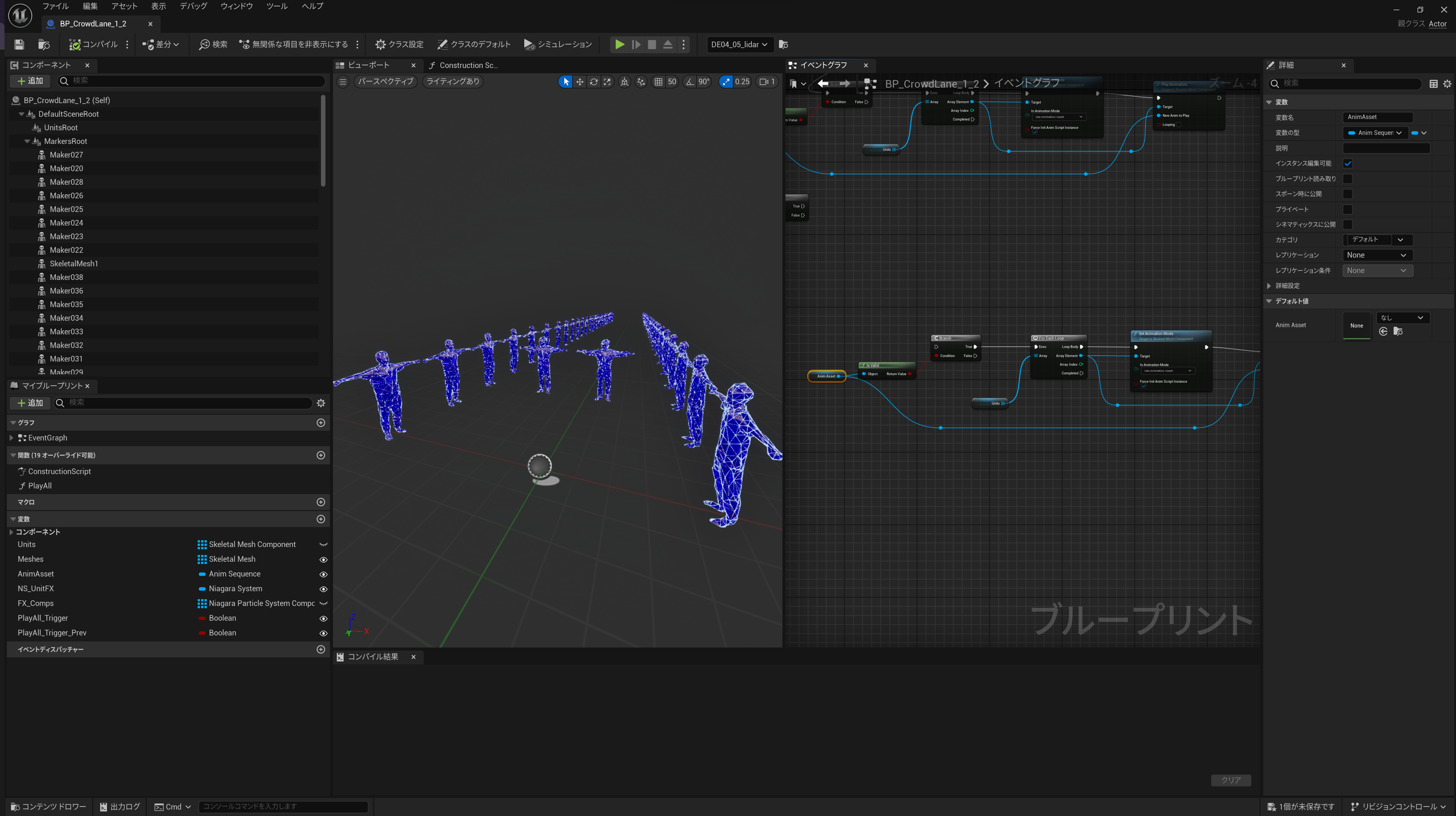
・CGモーションデータについて
実際の映像にあるように今回は1パートにつき2つの学生モデルと、複数のバックダンサーモデル(ワイヤーフレームなどであしらった人形)が存在します。
そういった中、1モデルずつ、当日生成されるアニメーションを適用していると手間かつ取り違えが発生しかねません。そのため、ブループリントでパートごとにモデルをグループ化し、アニメーション情報を外部変数化。この変数にセットするアニメーションを差し替えると、ブループリント内部のモデルのアニメーションが全て変更されるという仕組みにしておきました。
そういった中、1モデルずつ、当日生成されるアニメーションを適用していると手間かつ取り違えが発生しかねません。そのため、ブループリントでパートごとにモデルをグループ化し、アニメーション情報を外部変数化。この変数にセットするアニメーションを差し替えると、ブループリント内部のモデルのアニメーションが全て変更されるという仕組みにしておきました。
・モーション動画データについて
ここでは効率的なデータ連携というより、UE5を使った生成動画の簡易的な実写合成に関して考えます。
今回はこちらの事例 ( https://note.com/pridask/n/n0883b4f42edd)にならい、
・ 生成動画の背景を透過させ人物だけが写る状態化
・ 本動画を平面アクタ(板ポリ)に対して貼り付けし、シーンに配置
・ 動画(=板ポリ)が常にカメラに正体するように動く設定
という流れで、実写合成をしています。
そのためシーン上で側面などを見ると以下のようにペラペラな状態ですが…
今回はこちらの事例 ( https://note.com/pridask/n/n0883b4f42edd)にならい、
・ 生成動画の背景を透過させ人物だけが写る状態化
・ 本動画を平面アクタ(板ポリ)に対して貼り付けし、シーンに配置
・ 動画(=板ポリ)が常にカメラに正体するように動く設定
という流れで、実写合成をしています。
そのためシーン上で側面などを見ると以下のようにペラペラな状態ですが…

カメラで撮影すると、以下のようにペラペラには見えない(見えにくい)という仕組みです。

あくまで平面なので極端にカメラを動かすと違和感が強くなります。とはいえ、カメラの動きが大きくなければ、十分に自然な映像が撮影できるのかなと思っています。
一方で、前述したようにCGで人やモーションを作ると、カメラアングルの自由度は高いですし、CG的な演出(パーティクルをモデルの表面から出すなど)も適用しやすいとは思います。ただモデリングやモーション作りは大変です。また、表情作りなども考慮しだすと、尚のことです。
という中で、動画生成AIとCGによる実写合成というのは、新しい映像制作手段として面白そうだなと思いました。
(もちろん、全てを動画生成で対応するという手段もありうるわけですが。)
一方で、前述したようにCGで人やモーションを作ると、カメラアングルの自由度は高いですし、CG的な演出(パーティクルをモデルの表面から出すなど)も適用しやすいとは思います。ただモデリングやモーション作りは大変です。また、表情作りなども考慮しだすと、尚のことです。
という中で、動画生成AIとCGによる実写合成というのは、新しい映像制作手段として面白そうだなと思いました。
(もちろん、全てを動画生成で対応するという手段もありうるわけですが。)
<!—— SHARE ——>
-
view more --->小山田 圭佑Keisuke Oyamada
============== -
view more --->平川 智也Tomoya Hirakawa
==============.works体験!さわれる!?不思議な未来の天気 -
view more --->樋口 建Takeru Higuchi
==============.worksはままつオトミヤゲ -
view more --->浅野 聖也Seiya Asano
============== -
view more --->柏木 爽良Sara Kashiwagi
============== -
view more --->村越 海斗Kaito Murakoshi
==============
<‑‑
‑‑>
.column

.column
.column

タグ一覧
#次世代メディアデータ基盤#メディアソリューション#TV視聴ログ#GPS位置情報データ#メディア・コンテンツ開発#レシピデータ#自然言語処理#音声処理#表情感情推定#脳波#画像生成#text2image#Diffusion Model#3Dモデリング#PIFu#Mixamo#音声合成#Zero-Shot learning#Multilingual TTS#最適化#イベント登壇#人工知能学会#Developers Summit#デブサミ#エモテク#TV番組分析#SNSデータ#声質変換#Voice Conversion#Retrieval-based Voice Changer#image to 3d#NeRF#Volume Rendering#3D Reconstruction#空中触覚デバイス#フォトグラメトリ#初音ミク#AIラッパー#雑誌データ分析#リアルタイム生成#プロフィール推定#音楽生成#LLM#台本データ#3D Gaussian Splatting#CVPR#歌詞生成#センサーデータ#データサイエンスインターン#Kaggle#書籍執筆#動画生成#VibeCoding#生成AI#CG#映像制作#動画生成AI